


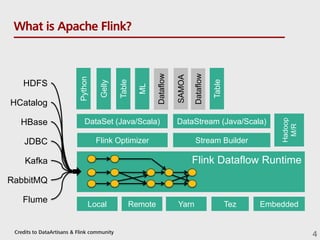
![Technology inside Flink
case class Path (from: Long, to:
Long)
val tc = edges.iterate(10) {
paths: DataSet[Path] =>
val next = paths
.join(edges)
.where("to")
.equalTo("from") {
(path, edge) =>
Path(path.from, edge.to)
}
.union(paths)
.distinct()
next
}
Cost-based
optimizer
Type extraction
stack
Task
scheduling
Recovery
metadata
Pre-flight (Client)
Master
Workers
DataSourc
e
orders.tbl
Filter
Map
DataSourc
e
lineitem.tbl
Join
Hybrid Hash
build
HT
probe
hash-part [0] hash-part [0]
GroupRed
sort
forward
Program
Dataflow
Graph
Memory
manager
Out-of-core
algos
Batch &
Streaming
State &
Checkpoints
deploy
operators
track
intermediate
results
Credits to DataArtisans & Flink community 5](https://image.slidesharecdn.com/sqlonstreams2share-160810063345/85/Towards-sql-for-streams-5-320.jpg)








Towards sql for streams
- 1. SQL on Streams powered by Apache Flink and Apache Calcite? Radu Tudoran
- 2. Titled Explained (motivation) Why SQL?Why Streaming? ● API to your database and other date lakes ● Ask for what you want, system decides how to get it ● Query planner (optimizer) converts logical queries to physical plans ● Standard & Mathematically sound language ● Opportunity for novel data organizations & algorithms ● Existing knowhow with rich pool of experts ● Most data is produced as a stream ● Streams are everywhere: devices, web, services, logs, traces, (social) media ● No delay – receive, process and deliver instantly and continuously ● Opportunity for novel services and businesses value extraction ● Better interconnected cloud services Why query streams? Duality: ● “Your database is just a cache of my stream” ● “Your stream is just change-capture of my database” ● “Data is the new oil” ● Treating events/messages as data allows you to extract and refine them ● Declarative approach to streaming applications
- 3. Outline Flink and Table API Calcite SQL batch SQL stream Open thoughts…
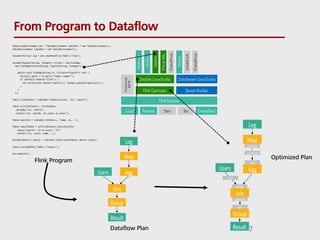
- 4. What is Apache Flink? Python Gelly Table ML SAMOA Flink Optimizer DataSet (Java/Scala) DataStream (Java/Scala) Stream Builder Hadoop M/R Local Remote Yarn Tez Embedded Dataflow Dataflow Flink Dataflow Runtime HDFS HBase Kafka RabbitMQ Flume HCatalog JDBC Credits to DataArtisans & Flink community 4 Table
- 5. Technology inside Flink case class Path (from: Long, to: Long) val tc = edges.iterate(10) { paths: DataSet[Path] => val next = paths .join(edges) .where("to") .equalTo("from") { (path, edge) => Path(path.from, edge.to) } .union(paths) .distinct() next } Cost-based optimizer Type extraction stack Task scheduling Recovery metadata Pre-flight (Client) Master Workers DataSourc e orders.tbl Filter Map DataSourc e lineitem.tbl Join Hybrid Hash build HT probe hash-part [0] hash-part [0] GroupRed sort forward Program Dataflow Graph Memory manager Out-of-core algos Batch & Streaming State & Checkpoints deploy operators track intermediate results Credits to DataArtisans & Flink community 5
- 6. Table API 6 • API for “SQL-like” queries/ expression language on the analytics pipeline • Build as abstraction in Java/Scala on top of DataSet (batch) and extended for DataStream (stream) • Enables to apply relational operators: selection, aggregation, joins • Enables to register as tables native data structures (DataSet, DataStream) and external sources • Tables can be converted back to native data structures StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment tableEnv = TableEnvironment.getTableEnvironment(env); // existing stream DataStream ord = … // register the DataStream ord as table "Orders" with fields user, product, and amount tableEnv.registerDataStream("Orders", ord, "user, product, amount"); TableSource custTS = new CsvTableSource("/path/to/file", ...) // register a `TableSource` as external table "Customers" tableEnv.registerTableSource("Customers", custTS) // convert a DataSet into a Table Table custT = tableEnv .toTable(orders, “user, amount") .where(“amount >'100'") .select("name") Table Environment Table Creation Table Usage
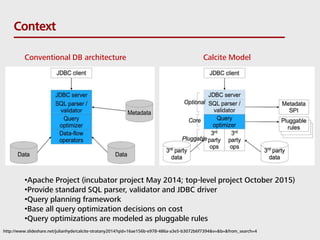
- 7. From Program to Dataflow 7 Flink Program Dataflow Plan Optimized Plan
- 8. Outline Flink and Table API Calcite SQL batch SQL stream Open thoughts…
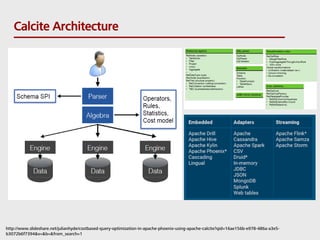
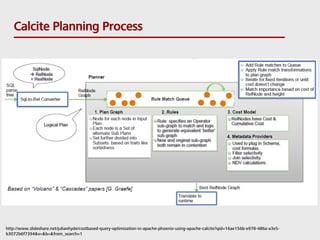
- 9. Context http://www.slideshare.net/julianhyde/calcite-stratany2014?qid=16ae156b-e978-486a-a3e5-b3072b6f7394&v=&b=&from_search=4 Conventional DB architecture Calcite Model •Apache Project (incubator project May 2014; top-level project October 2015) •Provide standard SQL parser, validator and JDBC driver •Query planning framework •Base all query optimization decisions on cost •Query optimizations are modeled as pluggable rules
- 12. Outline Flink and Table API Calcite SQL Analytics Open thoughts…
- 13. Analytics Traditional batch analytics • Repeated queries on finite and changing data sets • Queries join and aggregate large data sets • Data is fully available Stream analytics • “Standing” query produces continuous results from infinite input stream • Query computes aggregates on high-volume streams • A StreamSQL query runs forever and produces results continuously • Query’s focus needs to evolve with the stream How to compute aggregates on infinite streams?
- 14. Stream-table duality select * from Orders where units > 1000 select stream * from Orders where units > 1000 A a stream can be used as a table and Retrieve orders from now to +∞ …and a table can be used as a stream Retrieve elements from -∞to now Duality property allows to convert one to the other Orders (think of an eCommerce service) is both Calcite syntax: use the stream keyword Challenge: Where to actually find the data? That’s up to the system
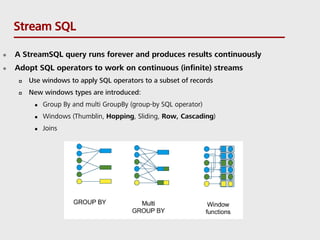
- 15. Stream SQL A StreamSQL query runs forever and produces results continuously Adopt SQL operators to work on continuous (infinite) streams Use windows to apply SQL operators to a subset of records New windows types are introduced: Group By and multi GroupBy (group-by SQL operator) Windows (Thumblin, Hopping, Sliding, Row, Cascading) Joins
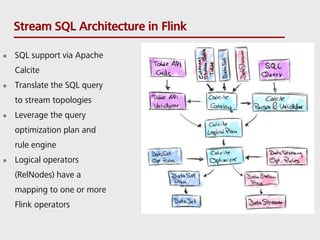
- 16. Stream SQL Architecture in Flink SQL support via Apache Calcite Translate the SQL query to stream topologies Leverage the query optimization plan and rule engine Logical operators (RelNodes) have a mapping to one or more Flink operators
- 17. Example SELECT STREAM TUMBLE_END(time, INTERVAL '1' DAY) AS day, location AS room, AVG((tempF - 32) * 0.556) AS avgTempC FROM sensorData WHERE location LIKE 'room%' GROUP BY TUMBLE(time, INTERVAL '1' DAY), location val avgRoomTemp: Table = tableEnv.ingest("sensorData") .where('location.like("room%")) .partitionBy('location) .window(Tumbling every Days(1) on 'time as 'w) .select('w.end, 'location, , (('tempF - 32) * 0.556).avg as 'avgTempCs) Calcite style Flink style
- 18. Outline Flink and Table API Calcite SQL Analytics Open thoughts…
- 19. Conclusions Observations Big Data trend is to move to uniform APIs (SQL, Apache Beam) Towards complete decoupling of all functionalities across software stack Stream and DB have a duality property SQL is compatible with streams – within windows New data service systems Credits for the slide materials Apache Flink Community and DataArtisans Apache Calcite Community 19